Technique PDF7:Performing OCR on a scanned PDF document to provide actual text
Applicability
Scanned PDF documents
This technique relates to:
- 1.4.5: Images of Text (Sufficient)
- 1.4.9: Images of Text (No Exception) (Sufficient)
Description
The intent of this technique is to ensure that visually rendered text is presented in such a manner that it can be perceived without its visual presentation interfering with its readability.
A document that consists of scanned images of text is inherently inaccessible because the content of the document is images, not searchable text. Assistive technologies cannot read or extract the words; users cannot select, edit, resize, or reflow text nor can they change text and background colors; and authors cannot manipulate the PDF for accessibility.
For these reasons, authors should use actual text rather than images of text, using an authoring tool such as Microsoft Word or Oracle Open Office to author and convert content to PDF.
If authors do not have access to the source file and authoring tool, scanned images of text can be converted to PDF using optical character recognition (OCR). Adobe Acrobat Pro can then be used to create accessible text.
Examples
Example 1: Generating actual text rather than images of text using Adobe Acrobat 9 Pro
This example is shown with Adobe Acrobat Pro. There are other software tools that perform similar functions. See the list of other software tools in .
This example uses a simple one-page scanned image of text. To ensure that actual text is stored in the document, perform the following steps:
- Scan the document using as high a resolution as possible to improve the OCR performance.
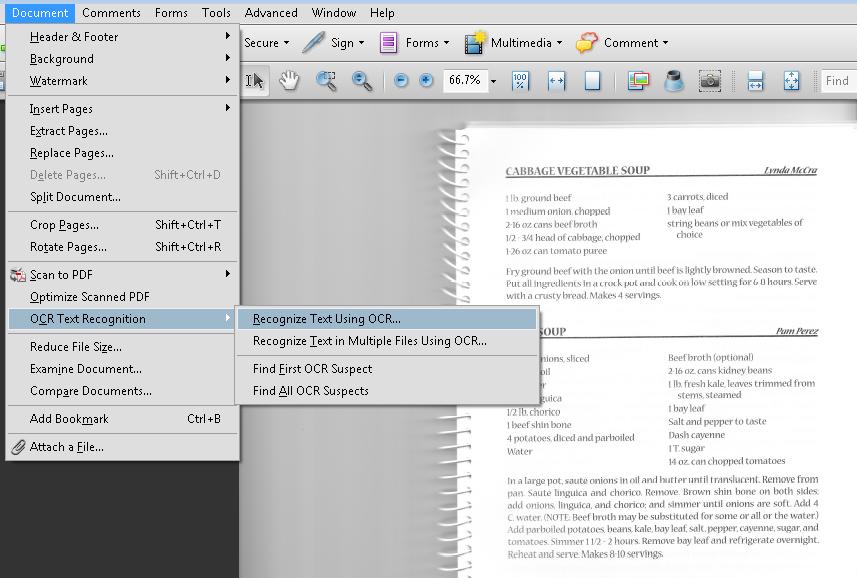
- Load the scanned document in Acrobat Pro. Select Document > OCR Text Recognition > Recognize Text Using OCR...
- In the next dialog, select the All Pages radio button under Pages (or Current Page if you are converting only one page), and then select OK.
- Under the Settings list, select Edit. In the next dialog, select Formatted Text and Graphics in the PDF Output Style drop-down list. This is important for ensuring accessibility.
- Depending on the resolution and how clear the text was, OCR converts images of words and characters to actual text. Text that Acrobat Pro does not recognize is listed as an "OCR suspect," or text element that Acrobat suspects was not recognized correctly.
- To fix the suspects, choose Document > OCR Text Recognition > Find First OCR Suspect. Acrobat Pro presents each suspect one at a time, which can be corrected using Acrobat Pro touchup tools.
- Run Advanced > Accessibility > Add Tags to Document
- Test for accessibility: Advanced > Accessibility > Full Check...
Alternatively, you can use Document > OCR Text Recognition > Find All OCR Suspects to display all OCR suspects at the same time for faster editing.
The following image shows a scanned one-page document in Adobe Acrobat Pro.
The next image shows the converted content after adding tags to the document. It will probably be necessary to use the TouchUp Reading Order tool and the Tags panel to tag the content properly for the intended final document. For this example, the image of the spiral book binding was tagged in the conversion. The TouchUp Reading Order tool was used to hide the image as a background (decorative) image (see ). The recipe titles were tagged as first level headers.
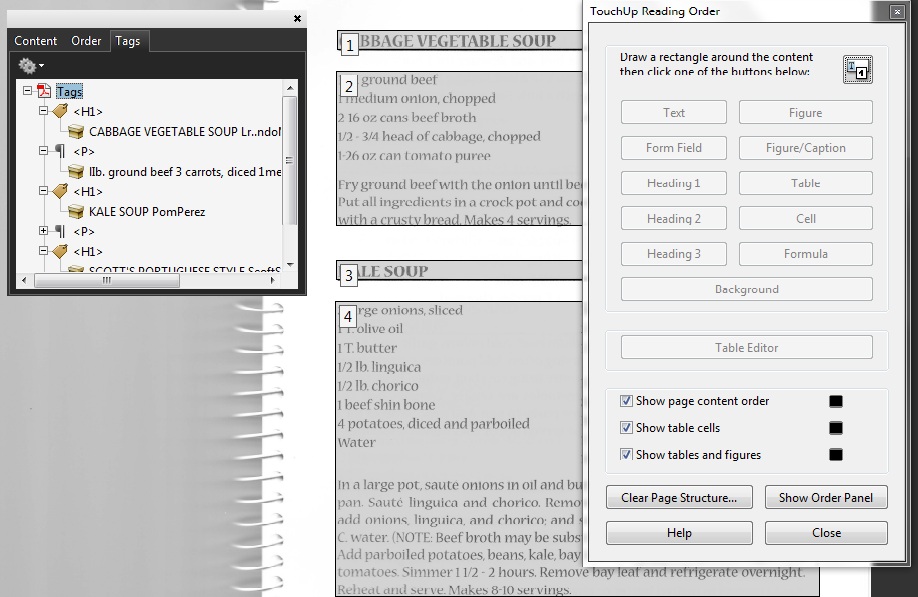
Note: Acrobat Pro may automatically add tags when the file is run through OCR.
This example is shown in operation in the working example of generating actual text and the result of performing OCR.
Other sources
No endorsement implied.
Tests
Procedure
-
For each page converted to text using OCR, ensure that the resulting PDF has been converted correctly, using one of the following ways:
- Read the PDF document with a screen reader or a tool that reads aloud, listening to hear that all text is read correctly and in the correct reading order.
- Save the document as text and check that the converted text is complete and in the correct reading order.
- Use a tool that is capable of showing the converted content to open the PDF document and verify that all text was converted and is in the correct reading order.
- Use a tool that exposes the document through the accessibility API and verify that all text was converted and is in the correct reading order.
Expected Results
- #1 is true.